EMAIL SUPPORT
dclessons@dclessons.comLOCATION
USAmazon RedShift
Amazon RedShift:
It is the fast, petabyte-scale data warehouse service which is designed for OLAP scenarios and is mostly used in high performance analysis and reporting of large datasets.
It gives you fast querying capabilities over structured data using standard SQL commands. It can connect well with ODBC and JDBC which further helps to integrates with various data loading, reporting, datamining, and analytics tool.
Clusters and Nodes:
A cluster is composed of a leader node and one or more compute nodes. A clients interacts directly with leader nodes and compute nodes are transparent to external applications.
Amazon RedShifts supports Six different nodes types and each can be of different CPU, memory and Storage and which are further grouped in to Dense compute or Dense Storage class.
A Dense Compute nodes types supports clusters up to 326TB using fast SSD where as Dense storage nodes supports clusters up to 2PB using large magnetic disks.
Following figure shows component of Amazon RedShift Dataware house cluster.
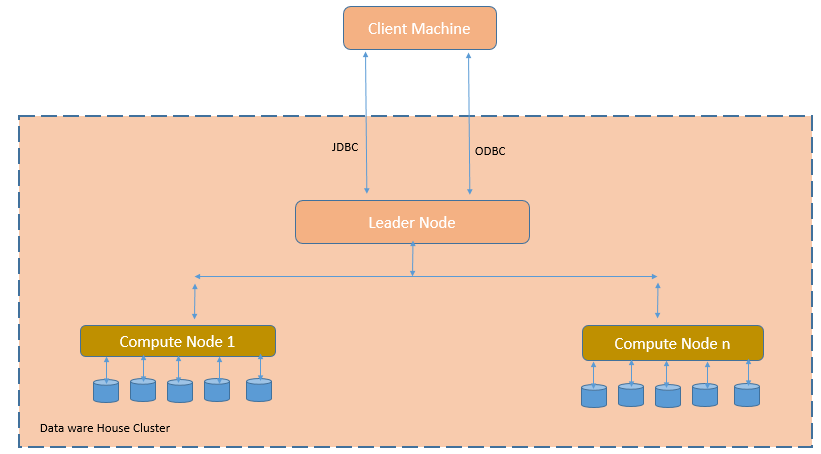
Each cluster contains one or more databases. User data for each table is distributed across the compute nodes. Your application or SQL client communicates with Amazon Redshift using standard JDBC or ODBC connections with the leader node, which in turn coordinates query execution with the compute nodes. Your application does not interact directly with the compute nodes.

Comment
TABLE OF CONTENTS
- Amazon S3- Basic Features
- Amazon S3 Advance Feature
- Amazon Glacier
- LAB Amazon Simple Storage Service
- LAB Setting up a Static Website
- LAB Enabling Versioning
- LAB Lifecycle Policy for S3 Bucket
- LAB: Create S3 Bucket & Upload Image & View Over browser
- LAB: Install AWS CLI
- LAB: Configure Lembda to upload an object in S3 Bucket
- Creating Custom VPC
- How to Attach Multiple IP to ENI-Instance
- How to Configure Launch Configuration & Auto Scaling
- How to Configure VPC Peering
- How to Configure VPN for VPC
- How to Configure VPC Tunneling
- How to Configure VPC with Private Subnet & Connect to DC
- How to Create Template for CloudFormation
- How to Configure Cloud Formation
- LAB: Configure Auto-Scaling & validation
RECENT POSTS
- Installing Context-Aware Network Access Control using Cisco ISE Policies
- Designing Network Access Control that is Scalable using Cisco ISE Architecture
- Enterprise Network Access Control and Policy Enforcement using Cisco ISE
- Secure Device Administration and Network Access Using AAA Architecture
- Designing Enterprise-Class Hybrid Cloud Connectivity Using AWS Networking Services
- Exploring Core AWS Networking and Messaging Concepts for Modern Cloud Architectures
- Understanding Key AWS Services for Modern Cloud Architectures
- Building a Strong AWS Foundation with Amazon S3, EC2, and Virtual Private Cloud
- Understanding the ENSDWI Course: Advanced Cisco SD-WAN (Viptela) Concepts
- A Complete Guide to the DCACI-A Course: Mastering Advanced Cisco ACI Concepts



LEAVE A COMMENT
Please login here to comment.