EMAIL SUPPORT
dclessons@dclessons.comLOCATION
USAmazon Dynamo DB
Following are the characteristics of the Dynamo DB:
- It Simplifies hardware provisioning, Setup, configuration, replication and cluster scaling of NoSQL database.
- It is fully managed NoSQL database which is fast and provides low latency performance
- It automatically distributes data and traffic for a table over multiple partitions
- It also automatically add enough infrastructure capacity to support requested throughput levels and it adds or removes infrastructure and adjust the internal partition accordingly.
- To provide fast performance, all table data is stored on high performance SSD disk drivers.
- Dynamo DB performance, transaction rates, and its overall throughput can be monitored by Amazon Cloud Watch.
- It also provide automatic high availability and durability by replicating data across multiple zones with in AWS regions.
Data Model:
There are three data models which includes tables, items, and attributes. Below figure shows the appropriate relation between them.
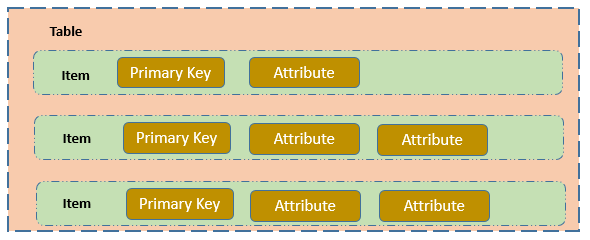
Each item also has primary key that uniquely identifies the item.
Amazon Dynamo DB only requires that a table have a primary key, but it does not require you to define all of the attribute names and data types in advance. Individual items in an Amazon Dynamo DB table can have any number of attributes, although there is a limit of 400KB on the item size.
Each attribute in an item is a name/value pair. An attribute can be a single-valued or multi-valued set. For example, a book item can have title and authors attributes. Each book has one title but can have many authors. The multi-valued attribute is a set; duplicate values are not allowed. Data is stored in Amazon Dynamo DB in key/value pairs such as the following:
Id = 101
ProductName = "Book DCLESSONS Title"
ISBN = "143–0123456789"
Authors = [ "Author A", "Author B" ]
Price = 3.22
Dimensions = "9.5 x 10.0 x 0.6"
PageCount = 1000
InPublication = 2
ProductCategory = "Book"
}
Applications can connect to the Amazon Dynamo DB service endpoint and submit requests over HTTP/S to read and write items to a table or even to create and delete tables. DynamoDB provides a web service API that accepts requests in JSON format.
Data Types
Amazon DynamoDB supports large number of data types. Which are discussed below.
Scalar Data Types
A scalar type represents exactly one value. Amazon DynamoDB supports the following five scalar types:
- String Text and variable length characters up to 400KB. Supports Unicode with UTF8 encoding
- Number Positive or negative number with up to 38 digits of precision
- Binary Binary data, images, compressed objects up to 400KB in size
- Boolean Binary flag representing a true or false value
- Null Represents a blank, empty, or unknown state. String, Number, Binary, Boolean cannot be empty.

Comment
TABLE OF CONTENTS
- Amazon S3- Basic Features
- Amazon S3 Advance Feature
- Amazon Glacier
- LAB Amazon Simple Storage Service
- LAB Setting up a Static Website
- LAB Enabling Versioning
- LAB Lifecycle Policy for S3 Bucket
- LAB: Create S3 Bucket & Upload Image & View Over browser
- LAB: Install AWS CLI
- LAB: Configure Lembda to upload an object in S3 Bucket
- Creating Custom VPC
- How to Attach Multiple IP to ENI-Instance
- How to Configure Launch Configuration & Auto Scaling
- How to Configure VPC Peering
- How to Configure VPN for VPC
- How to Configure VPC Tunneling
- How to Configure VPC with Private Subnet & Connect to DC
- How to Create Template for CloudFormation
- How to Configure Cloud Formation
- LAB: Configure Auto-Scaling & validation
RECENT POSTS
- Installing Context-Aware Network Access Control using Cisco ISE Policies
- Designing Network Access Control that is Scalable using Cisco ISE Architecture
- Enterprise Network Access Control and Policy Enforcement using Cisco ISE
- Secure Device Administration and Network Access Using AAA Architecture
- Designing Enterprise-Class Hybrid Cloud Connectivity Using AWS Networking Services
- Exploring Core AWS Networking and Messaging Concepts for Modern Cloud Architectures
- Understanding Key AWS Services for Modern Cloud Architectures
- Building a Strong AWS Foundation with Amazon S3, EC2, and Virtual Private Cloud
- Understanding the ENSDWI Course: Advanced Cisco SD-WAN (Viptela) Concepts
- A Complete Guide to the DCACI-A Course: Mastering Advanced Cisco ACI Concepts



LEAVE A COMMENT
Please login here to comment.