EMAIL SUPPORT
dclessons@dclessons.comLOCATION
USOpenStack Block Object and File Share Openstack storage
Storage Option:
Thera are two types of storage option mostly available to provide storage solution to compute nodes and further to instances.
- Ephemeral Storage
- Persistent Storage
Ephemeral Storage:
This is non-persistence storage, in which as soon as VM is terminated, it loses the associated disk. In working as soon as any VM is booted, glance image downloaded on compute node and this image is used as first disk for nova instance which further provides ephemeral storage. As the name suggests, anything stored will be lost as soon as VM is terminated.
Persistent Storage:
This type of storage means, even though the VM is powered off the storage and its data will be available. Persistent storage is divided in to three options:
- Object Storage
- File Storage
- Block Storage
What is object storage:
In object storage, data is stored in from of objects via RESTful HTTP API. By this type of storage, even though nodes fails, data are not lost and these type of storage can be scaled infinitely.
- In the object Storage, Data are stored as binary large objects (blobs) with multiple replicas on Object Storage servers.
- Object Storage are accessed using an API called REST or SOAP. And the data cannot be accessed by file protocol such as BFS, SMB or CIFS.
- These type of storage are not suitable for high performance requirement or the system that frequently changes data in database.
Swift: Object Storage
Swift is the Object storage service provided by Open Stack and was developed by joint efforts of NASA and Rack Space.
There are following benefits of using Swift as object storage solution:
- Highly Scalable
- On-Demand storage solution
- Elastic in nature as storage can be increased or decreased
Swift Architecture:
Swift Architecture is distributed in nature, and it also prevent the single point of failure and can be scaled horizontally. There are following Swift components as discussed below:
- Swift Proxy Server: This server, accepts the incoming request either via HTTP or OpenStack object API. It accepts the request for file upload, metadata updation, and container creation.
- Proxy Server: This server is mostly deployed in memcached to improve performance and mostly used for caching
- Account Server: This server manages the account that defines the object and its associated storage service. It also maintains the list of containers associated to account.
- Container Server: Container is basically user defined storage area , with in swift account. It maintains the list of objects stored in particular container. It is just like folders in windows systems.
- Object Server: It manages the object in containers. This server defines where and how actual data and its metadata are stored and every object belongs to a container.
In swift object storage solution, when we need to search, retrieve and index any data on object storage device, Meta data is used. These metadata are stored with object itself in key/value pairs.
How Swift is physically designed:
By default, a swift cluster storage has design considers the replica if three. Once data is written it si spread across other two redundant replicas.
Swifts isolates failures, and to achieve this, swift defines the new hierarchy that helps abstract the logical organization of data from physical one.
Region: As Swift is a geographically distributed environment, data can be sent to multiple nodes that are placed in to different regions. Swift to support the read/write function, it favor the data that are closer to read and while write, data is written locally and then is transferred to rest of regions.
Zones: Unser Regions come zones, which defines availability level that swift provides. To create zone, grouping of storage resources such as rack or storage node is done.
Storage nodes: Storage server are referred as Storage nodes and a group of storage nodes froms the cluster that runs the swift processes and stores the account, containers and object data and its associated Meta data.
Storage Device: It is smallest unit of storage in swift data stack. It can be internal storage node device or connected via external link to collection of disk in drive enclosure.
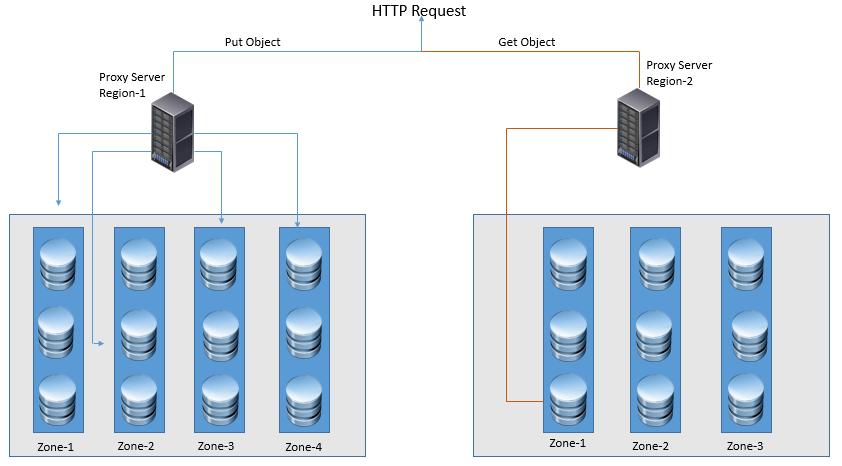
Swift Ring:
In Swift the logical layout of object data is mapped to a path based on the account, container and object hierarchy. In the context of OpenStack, the account maps to the tenant. Each tenant can have multiple containers, which are like folders in the filesystem, and finally the object belongs to a container just like a file belongs to a folder in convention filesystem based storage.

Comment
TABLE OF CONTENTS
RECENT POSTS
- Installing Context-Aware Network Access Control using Cisco ISE Policies
- Designing Network Access Control that is Scalable using Cisco ISE Architecture
- Enterprise Network Access Control and Policy Enforcement using Cisco ISE
- Secure Device Administration and Network Access Using AAA Architecture
- Designing Enterprise-Class Hybrid Cloud Connectivity Using AWS Networking Services
- Exploring Core AWS Networking and Messaging Concepts for Modern Cloud Architectures
- Understanding Key AWS Services for Modern Cloud Architectures
- Building a Strong AWS Foundation with Amazon S3, EC2, and Virtual Private Cloud
- Understanding the ENSDWI Course: Advanced Cisco SD-WAN (Viptela) Concepts
- A Complete Guide to the DCACI-A Course: Mastering Advanced Cisco ACI Concepts



LEAVE A COMMENT
Please login here to comment.